
高校数学[総目次]
数学B 第3章 統計的な推測
| スライド | ノート | 問題 | |
| 1. 確率変数と確率分布 | |||
| 2. 確率変数の期待値と分散 | |||
| 3. 確率変数の変換 | |||
| 4. 確率変数の和と期待値 | |||
| 5. 独立な確率変数と期待値・分散 | |||
| 6. 二項分布 | |||
| 7. 正規分布 | |||
| 8. 母集団と標本 | |||
| 9. 推定 | |||
| 10. 仮説検定 |

8.母集団と標本
8.1 標本
標本調査と全数調査
統計的な調査には,調査対象の全数を調べる全数調査と,調査対象の一部を調べて全体を推測する標本調査がある.
全数調査で有名なのが,5年に1度の国勢調査である.
一方,テレビの視聴率といったものは標本調査である.
調査対象を正確に知るには全数調査がよいと思うかもしれないが必ずしもそうではない.
調査対象が日本人全体といった場合には莫大な費用と時間を要するし,あるいは製品の耐用年数の検査の場合には全製品を壊れるまで使い続けなければならず,全数調査がそもそも意味を持たなくなってしまう.
また,経済成長率のように現時点で測定不可能な要素を含む場合もある.
標本調査におけるいくつかの用語
母集団:調査対象全体
標本 :母集団から選ばれた要素の集合
抽出 :母集団から標本を抜き出すこと
母集団の大きさ:母集団の要素の個数
標本の大きさ :標本の要素の個数
無作為抽出:調査対象をランダムに選ぶこと
無作為標本:無作為抽出によってえらばれた標本

8.2 母集団分布
まずは例 ~数学Ⅰデータの分析の復習~
あるクラスの40人の生徒に対して,1週間のうち何回公園を訪れるかを調査したところ次の表のような結果を得た.
| 回数 | $0$ | $1$ | $2$ | $3$ | $4$ | 計 |
|---|---|---|---|---|---|---|
| 度数 | $6$ | $6$ | $14$ | $10$ | $4$ | $40$ |
これらのデータから,公園を訪れる回数の平均値 $m$,分散 $s^2$,標準偏差 $s$ は 数学Ⅰ データの分析 で学んだように次のように計算される:
m&=\frac1{40}(0\cdot6+1\cdot6+2\cdot14+3\cdot10+4\cdot4)\\[5pt]
&=\frac{80}{40}=2\\[5pt]
s^2&=\frac1{40}\{(0\!-\!2)^2\!\cdot\!6\!+\!(1\!-\!2)^2\!\cdot\!6\!+\!(2\!-\!2)^2\!\cdot\!14\!+\!(3\!-\!2)^2\!\cdot\!10\!+\!(4\!-\!2)^2\!\cdot\!4\}\\[5pt]
&=\frac{56}{40}=1.4\\[5pt]
s&=\sqrt{1.4}
\end{align*}
\]
相対度数分布から確率分布へ
ここで,この40人から無作為に1人を選ぶと,その生徒が公園を訪れる回数は0,1,2,3,4のいずれかであり,そのどれになるかは確率の問題である.
公園を訪れる回数を $X$ とすると,確率は相対度数で求められる:
| $X$ | $0$ | $1$ | $2$ | $3$ | $4$ | 計 |
|---|---|---|---|---|---|---|
| 相対度数 | $\dfrac{6}{40}$ | $\dfrac{6}{40}$ | $\dfrac{14}{40}$ | $\dfrac{10}{40}$ | $\dfrac{4}{40}$ | $1$ |
つまり$X$ は「40人から1人を選ぶ」という試行の結果得られる数であり,その背後に確率が1つ対応しているのであるから確率変数であると考えることができる.
そして $X$ が従う分布はすぐ上の表から次のようになる.
| $X$ | $0$ | $1$ | $2$ | $3$ | $4$ | 計 |
|---|---|---|---|---|---|---|
| $P$ | $\dfrac{6}{40}$ | $\dfrac{6}{40}$ | $\dfrac{14}{40}$ | $\dfrac{10}{40}$ | $\dfrac{4}{40}$ | $1$ |
このとき確率変数 $X$ の期待値 $E(X)$,分散 $V(X)$,標準偏差 $\sigma(X)$ はそれぞれ次のように計算される.
E(X)&=0\cdot\frac6{40}+1\cdot\frac6{40}+2\cdot\frac{14}{40}+3\cdot\frac{10}{40}+4\cdot\frac3{40}\\[5pt]
&=\frac{80}{40}=2\\[5pt]
V(X)&=(0\!-\!2)^2\!\cdot\!\frac6{40}\!+\!(1\!-\!2)^2\!\cdot\!\frac6{40}\!+\!(2\!-\!2)^2\!\cdot\!\frac{14}{40}\!+\!(3\!-\!2)^2\!\cdot\!\frac{10}{40}\!+\!(4\!-\!2)^2\!\cdot\!\frac4{40}\\[5pt]
&=\frac{56}{40}=1.4\\[5pt]
\sigma(X)&=\sqrt{V(X)}=\sqrt{1.4}
\end{align*}
\]
以上により,
\[\begin{align*}
E(X)&=m\\[5pt]
V(X)&=s^2\\[5pt]
\sigma(X)&=s
\end{align*}\]
であることがわかる.
ここから一般論 ~母集団分布とは~
一般に,大きさ $N$ の母集団において,変量 $x$ のとり得る値で異なるものが
\[x_1,\ \ x_2,\ \ \cdots,\ \ x_n\]
の $n$ 個であるとし,それぞれの値をとる度数,すなわちその値をとる要素の個数が順に
\[f_1,\ \ f_2,\ \ \cdots,\ \ f_n\]
であるとする.
これは全数調査であるから
\[f_1+f_2+\cdots+f_n=N\]
である.
また表にまとめると次のようになる.
| 変量 | $x_1$ | $x_2$ | $\cdots$ | $x_n$ | 計 |
|---|---|---|---|---|---|
| 度数 | $f_1$ | $f_2$ | $\cdots$ | $f_n$ | $N$ |
変量 $x$ の分布は次のように相対度数で求めることができる.
| 変量 | $x_1$ | $x_2$ | $\cdots$ | $x_n$ | 計 |
|---|---|---|---|---|---|
| $P$ | $\dfrac{f_1}{N}$ | $\dfrac{f_2}{N}$ | $\cdots$ | $\dfrac{f_n}{N}$ | $1$ |
これをこの母集団における変量 $x$ の母集団分布という.
またその平均値,分散,標準偏差をそれぞれ母平均,母分散,母標準偏差という.
母集団から抽出された大きさ1の無作為標本の確率分布は,母集団分布と一致する
いまこの母集団から無作為に1つの要素を抽出し,その要素の変量の値を $X$ とすると,$X$ は「大きさ1の無作為抽出」という試行の結果から得られる数であるから確率変数であると考えることができる.
$X$ が従う分布は相対度数から次のようになる.
| 変量 | $x_1$ | $x_2$ | $\cdots$ | $x_n$ | 計 |
|---|---|---|---|---|---|
| $P$ | $\dfrac{f_1}{N}$ | $\dfrac{f_2}{N}$ | $\cdots$ | $\dfrac{f_n}{N}$ | $1$ |
見ての通り,すぐ上にあげた2つの分布は完全に同一のものとなっている.
換言すれば
「母集団分布」と「大きさ1の無作為標本の確率分布」は一致している
ということである.
従って確率変数 $X$ の期待値 $E(X)$,分散 $V(X)$,標準偏差 $\sigma(X)$ と,母平均 $m$,母分散 $\sigma^2$,母標準偏差 $\sigma$ との関係は次のようになる.
\[\begin{align*} E(X)&=m\\[5pt] V(X)&=\sigma^2\\[5pt] \sigma(X)&=\sigma \end{align*}\]

例題 10枚のカードがあり,調べてみると0,1,2が書かれたカードがそれぞれ5枚,2枚,3枚の計10枚であった.この10枚を母集団,カードの数字を変量とするとき,母平均,母分散,母標準偏差を求めよ.
解答例を表示する
母集団分布は次のようになる.
| 変量 | $0$ | $1$ | $2$ | 計 |
|---|---|---|---|---|
| $P$ | $\dfrac{5}{10}$ | $\dfrac{2}{10}$ | $\dfrac{3}{10}$ | $1$ |
いまこの母集団から無作為に1枚取り出し,カードに書かれた数を $X$ とするとき,$X$ が従う確率分布は上の母集団分布と一致する.すなわち $X$ が従う分布は次のようになる.
| $X$ | $0$ | $1$ | $2$ | 計 |
|---|---|---|---|---|
| $P$ | $\dfrac{5}{10}$ | $\dfrac{2}{10}$ | $\dfrac{3}{10}$ | $1$ |
・母平均$=E(X)=0\cdot\dfrac5{10}+1\cdot\dfrac2{10}+2\cdot\dfrac3{10}=\dfrac45$
・母分散
$E(X^2)=0^2\cdot\dfrac5{10}+1^2\cdot\dfrac2{10}+2^2\cdot\dfrac3{10}=\dfrac75$
よって
母分散$=V(X)=E(X^2)-\{E(X)\}^2$
$=\dfrac75-\left(\dfrac45\right)^2=\dfrac{19}{25}$
・母標準偏差$=\sigma(X)=\sqrt{\dfrac{19}{25}}=\dfrac{\sqrt{19}}5$

8.3 復元抽出と非復元抽出
復元抽出と非復元抽出
母集団から標本を抽出するとき,毎回元に戻して抽出を繰り返す方法を復元抽出といい,元に戻さないで抽出していく方法を非復元抽出という.
例 1から10の各数字が書かれた10枚のカードから,大きさ3の標本を抽出するとき,
復元抽出 :$10^3=1000$ 通りの標本ができる.
非復元抽出:選ぶ順番を考慮すると$_{10}{\rm P}_3=720$ 通りの標本ができる
補足
非復元抽出は,厳密には独立試行とならないが,抽出回数に比べて母集団の大きさが十分大きいとき,前の抽出結果が後の抽出にほとんど影響しないと考えて近似的に復元抽出と同様に独立試行であると考える場合がある.
8.4 標本平均
$n$ 回の復元抽出により得られた$n$個の確率変数は,すべて同じ分布に従う
母集団(という集合)から大きさ $n$ の無作為標本を抽出する,すなわち無作為に $n$ 個の要素を取り出して集合を作る.
この $n$ 個について,変量 $x$ の値を $X_1,X_2,\cdots,X_n$ とすると,これらは標本からの抽出という試行の結果によって定まる確率変数である.
例えば,1から6の各数字が書かれたカードが1枚ずつ,計6枚あるとしてこれを母集団とする.
ここからカードを無作為に1枚ずつ取り出しては戻すという操作を10回行い,$i$ 回目に取り出されたカードの数字を $X_i$ $(i=1,2,\cdots,10)$ とすると,これらは確率変数となり,各 $X_i$ は すべて同じ分布に従う:
| $X_i$ | $1$ | $2$ | $3$ | $4$ | $5$ | $6$ | 計 |
|---|---|---|---|---|---|---|---|
| $P$ | $\dfrac{1}{6}$ | $\dfrac{1}{6}$ | $\dfrac{1}{6}$ | $\dfrac{1}{6}$ | $\dfrac{1}{6}$ | $\dfrac{1}{6}$ | $1$ |
標本平均と標本標準偏差
次に,標本平均と標本標準偏差について説明する.標本平均 $\overline{X}$ と標本標準偏差 $s$ を次のように定義する.
標本平均と標本標準偏差
\[\begin{align*}
&\overline{X}=\frac{X_1+X_2+\cdots+X_n}n\\[5pt]
&s=\sqrt{\frac1n\sum_{k=1}^n(X_k-\overline{X})^2}
\end{align*}\]
これらは定義式からわかるように,観測された $n$ 個のデータについての平均値と標準偏差である.
また標本分散は標本標準偏差の2乗で $\displaystyle\frac1n\sum_{k=1}^n(X_k-\overline{X})^2$ となっている.
標本平均 $\overline{X}$ については次に示すように期待値 $E(\overline{X})$ が母平均に一致するが,標本分散についてはその期待値 $\displaystyle E\left(\frac1n\sum_{k=1}^n(X_k-\overline{X})^2\right)$ が母分散と一致していない.
詳しくはこのページの最下部にあるコラム~不偏分散を参照.
■標本平均の期待値と分散
これ以降の主役は標本平均
標本平均と標本標準偏差という2つの統計量を確認したが,今後我々の興味・関心は専ら標本平均である.
標本平均は例えば100個のデータを抽出したとしても,どのデータが抽出されたかによって値は確率的に変わるものであって,従って標本平均も1つの確率変数である.
そこで標本平均という確率変数の期待値と分散がどうなっているのか見ていこう.
ある母集団から大きさを $n$ の無作為標本を復元抽出し,変量 $x$ の値を $X_1,X_2,\cdots,X_n$ とする.
母平均を $m$,母標準偏差を $\sigma$ とすれば,各 $X_i$ $(i=1,2,\cdots,n)$ はすべて同じ分布(母集団分布)に従うから,すべての $\boldsymbol i$ で,
\[\begin{align*}
&E(X_i)=m\\[5pt]
&\sigma(X_i)=\sigma
\end{align*}\]
である.
従って,標本平均 $\overline{X}$ の期待値は,
\[\begin{align*}
E(\overline{X})&=E\left(\frac{X_1+X_2+\cdots+X_n}n\right)\\[5pt]
&=\frac{E(X_1)+E(X_2)+\cdots+E(X_n)}n\\[5pt]
&=\frac{nm}n\\[5pt]
&=m
\end{align*}\]
また,復元抽出では$X_1,X_2,\cdots,X_n$ は互いに独立であるから,
\[\begin{align*}
V(\overline{X})&=V\left(\frac{X_1+X_2+\cdots+X_n}n\right)\\[5pt]
&=\frac{V(X_1)+V(X_2)+\cdots+V(X_n)}{n^2}\\[5pt]
&=\frac{n\sigma^2}{n^2}\\[5pt]
&=\frac{\sigma^2}n\\[5pt]
\therefore \sigma(\overline{X})&=\sqrt{V(\overline{X})}=\frac\sigma{\sqrt n}
\end{align*}\]
ここでは復元抽出を仮定したが,母集団の大きさが標本の大きさ $n$ に比べて十分大きいときは,非復元抽出であっても近似的に復元抽出として考えることもある.
まとめ 母平均 $m$,母標準偏差 $\sigma$ の母集団から大きさ $n$ の無作為標本を抽出するとき,標本平均 $\overline{X}$ の期待値と標準偏差は
\[\begin{align*}
E(\overline{X})&=m\\[5pt] \sigma(\overline{X})&=\frac\sigma{\sqrt n} \end{align*}\]
補足
上の式から,標本の大きさ $n$ を大きくすると,標本平均 $\overline{X}$ の散らばり具合である標準偏差は0に近付いていくことがわかる.
例題 ある県の小学生全員を対象に鉛筆を何本持っているかを調査したところ,平均値(母平均)は40本,標準偏差(母標準偏差)は8本であることがわかった.この母集団から無作為に100人を選んだとき,この100人が持っている鉛筆の本数の平均 $\overline{X}$ の期待値 $E(\overline{X})$ と標準偏差 $\sigma(\overline{X})$ を求めよ.
解答例を表示する
上のまとめ から,標本平均 $\overline{X}$ の期待値 $E(\overline{X})$ は,母平均40と一致するから,
\[E(\overline{X})=40\]
また標本平均 $\overline{X}$ の標準偏差$\sigma(\overline{X})$ も上のまとめの式から
\[\sigma(\overline{X})=\frac{8}{\sqrt{100}}=\frac{8}{10}=0.8\]
8.5 標本平均の分布と正規分布
確率変数 $X_1+X_2+\cdots+X_n$ は正規分布にどんどん近付く
母平均 $m$,母分散 $\sigma^2$ の母集団から,大きさ $n$ の無作為標本を抽出し,それらの変量の値を $X_1,X_2,\cdots, X_n$ とすると,これらはみな同じ分布(母集団分布)に従う確率変数である.
いまこれら $n$ 個の確率変数の和をとり
\[X=X_1+X_2+\cdots+X_n\]
とすると $X$ もまた確率変数である.
ところでこのように確率変数の和をとることは,統計学において大変重要な意味を有している.
どういうことか?
実は $n$ の値を大きくしていくと,確率変数 $X$ はどんどん正規分布に近付いていくのである.
しかも母集団分布がいかなる分布であっても!である.
この事実はある母集団から抽出した大きさ $n$ の無作為標本の平均値
\[\overline{X}=\dfrac{X_1+X_2+\cdots+X_n}n\]
でも成り立つ.
そのことを例で確認してみよう.
標本平均の分布が正規分布に近付いていく様子
さいころを何回か投げることを考える.
確率変数 $X_k$ を $k$ 回目出た目とする.
$X_k$ のとりうる値は 1から6の6つである.
さいころを1回だけ投げる場合,どの目が出る確率も $\dfrac16(=0.166\cdots)$ となっており,確率分布は次のグラフのようになっている.
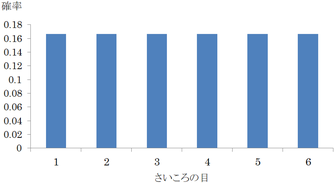
この段階では正規分布の影もない.
次に,さいころを2回投げたときの標本平均 $\dfrac{X_1+X_2}2$,すなわち2回の出た目の平均値を考える.
さいころを2回投げたとき,全部の目の出方は $6\times6=36$ 通りあって,出た目の合計は $2,3,4,\cdots 12$ の11通りある.
平均値は2で割って $1.0,1.5,2.0,\cdots6.0$ である.$\dfrac{X_1+X_2}2$ の確率分布を
\[P(X_1+X_2=k)=\left\{
\begin{array}{ll}
\dfrac{k-1}{36}&(2\leqq k\leqq7)\\[5pt]
\dfrac{13-k}{36}&(8\leqq k\leqq 12)
\end{array}\right.
\]
によって計算すると次のようになる.